POSTS
Using mongodb with automatic fail-over in a loopback nodeJs application
##Introduction
In this article I’ll explain how easy it is to configure automatic fail-over when using MongoDb as database server. I’ll present things in such a way you can easily do this yourself on a windows machine.
##What is fail-over?
Data and the especially the availability of data is crucial for an application. So, it makes a lot of sense to ensure that in case your database server goes down, the whole data handling is automatically taken over by another server. MongoDb is offering this by means the Replica Set functionality. In short, there is the notion of a primary database and multiple secundary databases.
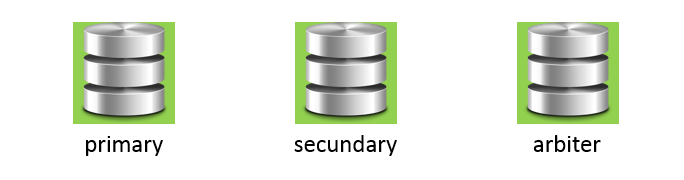
The primary database is the only writable instance, so all write operations must be against this primary database.
The secundary databases are read-only instances and it’s advised to have many secundaries. The more,the better. Data is always replicated from the primary. Now, when the primary fails, one of the secundaries becomes the primary. So, there is automatic recovery from a crash from the primary, the “farm” gets resilience against a single server failure. In the event that one of the secundaries fails, there is still the primary and the other secundaries.
The arbiter db is a special database instance that has no other function than deciding which secundary will take over (in other words: will become the primary) when the primary fails.
Following diagram illustrates the fail-over process:
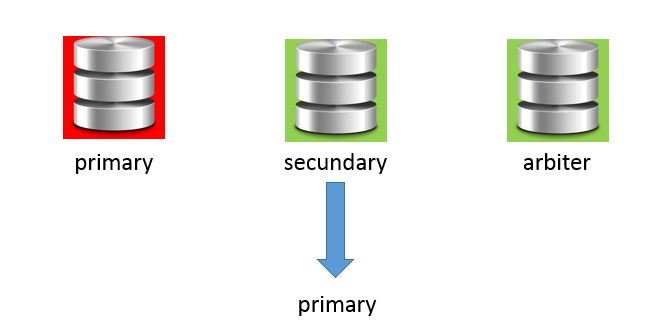
##Our test setup To ensure that you can try this out very easily on a windows box, we will install 3 mongo database on just one machine. Obviously, in production, these should be on different servers ! So, we create one primary, one secundary and an arbiter db.
Let’s first create 3 folders
md testdb1
md testdb2
md testdb3
and we start mongodb 3 times on a different port:
start "first" mongod --dbpath ./testdb1 --port 29001 --replSet "replicaset"
start "secundary" mongod --dbpath ./testdb2 --port 29002 --replSet "replicaset"
start "third" mongod --dbpath ./testdb3 --port 29003 --replSet "replicaset"
Notice we specify a replicaset called “replicaset”. Obviously, you can name it what you want.
##Configure the replica set In order to configure the replica set, we connect to the first instance, so the primary.
mongo --port 29001
in the mongo shell you can create variables. In fact, you can just run javascript. So, create a variable called testConfig:
var testConfig={
"_id":"replicaset",
"members":[
{"_id":0, "host":"localhost:29001","priority":10},
{"_id":1, "host":"localhost:29002"},
{"_id":2, "host":"localhost:29003","arbiterOnly":true}
]};
The first instance gets a priority property, which will increase the likelihood that the arbiter will nominate this instance as primary. The third instance has the arbiterOnly attribute. We are almost finished configuring (I told you, it’s easy):
rs.initiate(testConfig)
will initiate the configuration and will return
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
The shell will now indicate also that our current db is the primary. That may take a minute or so. ##Let’s check the replication to the secundary We are still connected to our primary and can add some data to a test database:
db.mydb.save({_id:1, value:"here we go with replication"});
Let’s connect now to the secundary and see if the data is there as well.
mongo --port 29002
Following find command will initially give an error
db.mydb.find()
error: { "$err" : "not master and slaveOk=false", "code" : 13435 }
We can fix this as follows:
db.setSlaveOk()
We you are able to retrieve the same record on the secundary.
db.mydb.find()
Try also that writing data the secundary will not be possible. ##Check things when the primary is down First connect to the secundary and kill the primary by simply closing the window of the primary (the one called ‘first’). You will notice that your cursor changes now from
replicaset:SECUNDARY>
to
replicaset:PRIMARY>
Try now adding a record. You will notice that this time adding a record works, since the secundary has now the role of the primary. Reconnect again the primary and check if the newly created record shows up in the primary as well. ##And now with a loopback based nodeJs application The above is great, but things should work also when working with data from an application (e.g. nodeJs). An application should be ignorant about primaries, secundaries and arbiters, the whole fail-over process must be transparent. In order to test things, I created a very small nodeJs app (based on Loopback, where from a angular client I send (in a loop) 10.000 records to the server. Now, the test is all about disconnecting the primary while this loop is running. You will notice that after a minute or so, the secundary takes over. Furthermore, when the primary gets online again, data are synced between the secundary and the primary. Obviously, there is data loss due to the time needed for switching from the primary to the secundary, but try to imagine the situation where there would not be no fail-over strategy? How long would your complete app be down before you it comes to your attention?
Just one note about the code. It’s important to formulate the connection string as follows:
{
"db": {
"url": "mongodb://localhost:29001,localhost:29002/failovertest?replicaSet=replicaset",
"name": "db",
"connector": "mongodb"
}
}
As you can see, the name of the replicaset is indicated in the connection string. You can find more info in the loopback documentation, which is becoming better, day by day.
You can find the sources of this small test on github Notice that for test purposes, our database are all on the same server. In production you will want to use different physical machines or even spread secundaries over different cloud providers. ##So, I don’t need any longer a backup strategy? You need definitely a backup strategy. Connect to the primary, drop a collection and you will notice that this drop is replicated almost immediately to all secundaries and your collection is gone for ever. See it this way, fail-over is all about data availability (making sure when one database node is down, another takes over as soon as possible). A backup is a strategy to prevent accidental data loss. So, you need both fail-over and backup.